我们的目标是用爬虫来干一件略污事情
最近听说煎蛋上有好多可爱的妹子,而且爬虫从妹子图抓起练手最好,毕竟动力大嘛。而且现在网络上的妹子很黄很暴力,一下接受太多容易营养不量,但是本着有人身体就比较好的套路,特意分享下用点简单的技术去获取资源。
以后如果有机会,再给大家说说日本爱情动(大)作(雾)片的种子搜索爬取,多多关注。

请先准备
作案工具
我们只准备最简单的
需要用到的包
也可以用下面的命令快速安装
干正事
从一次正常需求说起
每天在互联网上冲来冲去,浏览着大量的信息,观看这各种鼻血喷发的图片,于是作为新时代青年的我们,怎么能忍受被这些大量的垃圾信息充斥的互联网,我们要反抗,我们要下载!
请,看,下,图
↓

当你在网上冲浪的时候遇到这样的图片,我就问你:
虐不虐?虐死了!
下不下?下!
开始吧
获取图片的CSS选择器的规则
首先,我们需要定位我们需要的图片
根据我们之前的准备的作案工具,使用chrome来访问网页http://jandan.net/ooxx
然后打开开发者工具菜单 -> 更多工具 -> 开发者工具
看下图右边的神器
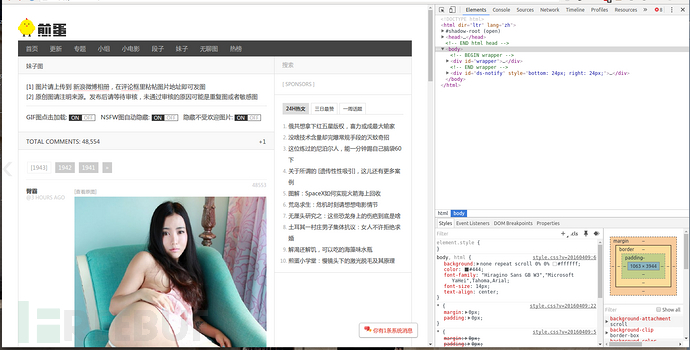
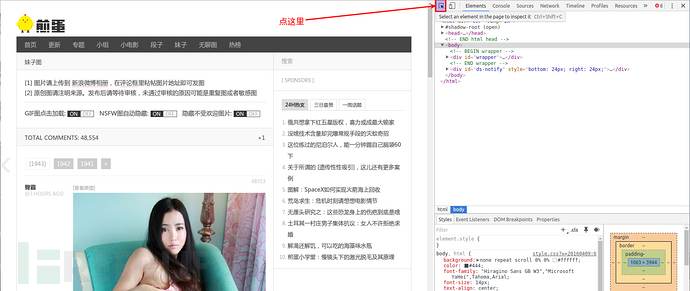
点击这个图标会出现块选择器,
鼠标移动我们感兴趣的部分
按照图片指示点击区域
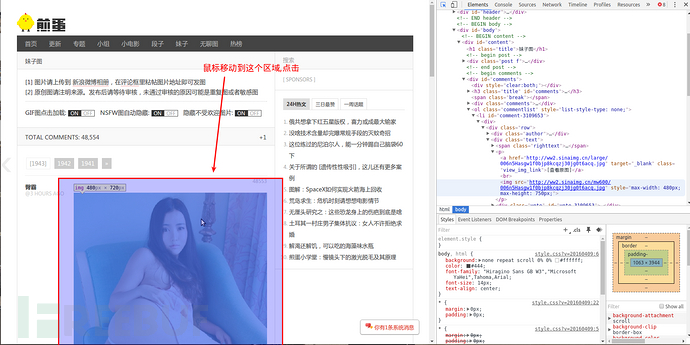
右边神器中就会出现我们所需要的img标签
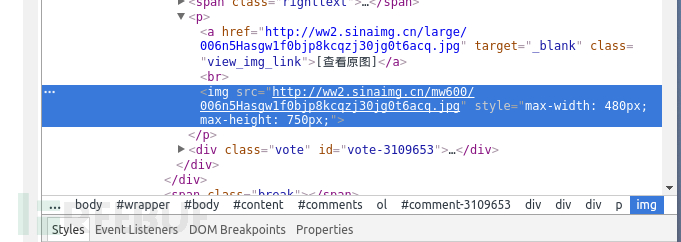
查看之前最后一个以#comments开头的标签,
它包含了所有img的子标签。
下面让我们来一些
神秘的事
打开cmd或者终端
输入python
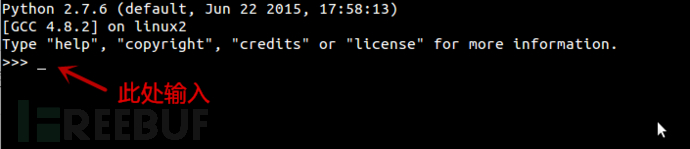
输入以下神秘代码
import requests
from bs4 import BeautifulSoup
res = requests.get('http://jandan.net/ooxx')
html = BeautifulSoup(res.text) for index, each in enumerate(html.select('#comments img')):
with open('{}.jpg'.format(index), 'wb') as jpg:
jpg.write(requests.get(each.attrs['src'], stream=True).content) 现在偷偷看一下你的当前目录
是不是有很多(污)的图片
咳咳是这样的
↓
名词解释
网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫的使用对很多工作都是很有用的,但是对一般的社区,也需要付出代价。使用爬虫的代价包括:
适用场景
是不是还不够
行踪不定的下期预告
转载请注明出处 AE博客|墨渊 » 手把手教你用Python爬虫煎蛋妹纸海量图片
发表评论